Test your agents with pinecall test — define conversation workflows in YAML, and a judge LLM evaluates your agent's behavior automatically.
Quick Start#
1. Create a spec file#
Create agent/specs/greeting.spec.yaml in your agent project:
agent: florencia
description: "Verify the agent greets correctly"
workflow: |
1. Say "Hola"
2. Verify the agent responds warmly with a greeting
3. Verify it mentions the business name
4. PASS if greeting is correct, FAIL if not2. Run the test#
pinecall test agent/specs/That's it. The judge LLM will converse with your agent, follow the workflow, and report pass/fail.
How It Works#
pinecall test uses a judge LLM (Claude Haiku by default) to test your agent:
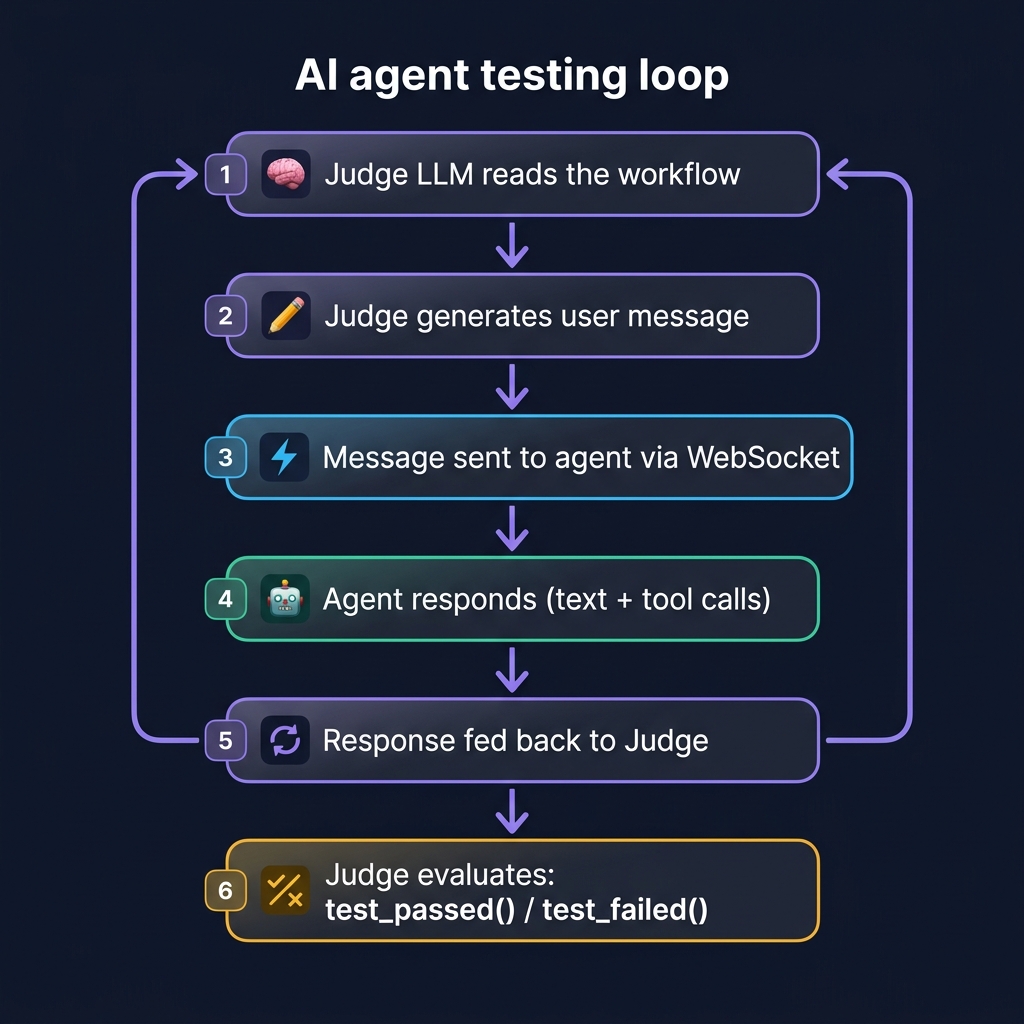
The judge has two tools:
test_passed(summary)— marks the workflow as passedtest_failed(reason)— marks the workflow as failed
The judge's text messages are sent directly to your agent as user messages. It acts like a real customer following a script.
Voice Mode#
By default pinecall test talks to your agent over text (fast and cheap). To exercise the real voice pipeline — STT, turn detection, TTS, barge-in — run the spec as an actual voice call.
In voice mode the judge is a real Pinecall agent (server-rendered voice) bridged to your agent: two agents, two WebSockets, one call. Each side runs the full STT → LLM → TTS → turn-detection pipeline, and neither side knows the other is a bot — to your agent it's a normal inbound call. The CLI records both voices to a WAV, opens a live browser player, and resolves the verdict when the judge calls test_passed() / test_failed().
Run it#
# Force voice mode with the flag…
pinecall test agent/specs/greeting.spec.yaml --voice
# …or declare `mode: voice` in the spec and run it normally
pinecall test agent/specs/greeting.spec.yamlRequirements: PINECALL_API_KEY + the judge LLM key (e.g. ANTHROPIC_API_KEY). No TTS/STT key needed — the judge's voice is rendered server-side.
Voice spec fields#
agent: pines
description: "Pines greets and answers a question (voice)"
mode: voice # run as a real voice call
voice: elevenlabs/professional-male # judge's TTS voice (default)
stt: flux # judge's STT (default: deepgram-flux)
language: en # optional language override
greeting: "Hi!" # optional: judge opens the call;
# omit → your agent greets first, judge waits
timeout: 45s # voice turns are slower than text
workflow: |
1. Greet the agent and ask what it can help with.
2. Verify it responds coherently and offers to help.
3. Ask "What is Pinecall?" and verify the answer is on-topic.
4. PASS if the conversation was coherent and helpful.Voice CLI flags#
| Flag | Description |
|---|---|
--voice <p/v> | Judge's TTS voice (e.g. elevenlabs/professional-male). Passing it also forces voice mode. |
--stt <prov> | Judge's STT (e.g. flux). Default: deepgram-flux. |
--record <file> | WAV output path. Default: <spec>.wav next to the spec. |
--no-listen | Don't auto-open the live browser player. |
--lang <code> | Language override (e.g. es). |
The judge speaks one short sentence per turn (it behaves like a real caller), the mixed call is recorded to a WAV next to the spec, and the transcript shows both sides per utterance.
Writing Specs#
Spec format#
Specs are YAML files ending in .spec.yaml or .spec.yml.
# Required fields
agent: florencia # Agent name (as registered with pc.agent())
workflow: | # Natural language workflow for the judge
1. Do something
2. Verify something
3. PASS or FAIL
# Optional fields
description: "Human-readable title" # Shown in test output
timeout: 45s # Per-turn timeout (default: 30s)
# Optional: override judge model
judge:
provider: anthropic # anthropic | openai | google | deepseek | ollama
model: claude-haiku-4-5 # Model name
maxTurns: 10 # Max conversation turns (default: 20)Workflow tips#
The workflow field is natural language — the judge LLM interprets it. Write it like instructions for a QA tester:
# ✅ Good — clear, actionable steps
workflow: |
1. Ask what services are available
2. Verify the agent lists at least 3 services with prices
3. Ask to book one of them
4. Verify the agent calls the booking tool
5. PASS if booking flow works, FAIL if anything breaks
# ❌ Bad — too vague
workflow: |
Test if the agent works correctlyBest practices:
- Number your steps for clarity
- Be specific about what "correct" means (dates, tool calls, content)
- Always end with explicit PASS/FAIL criteria
- Write in the same language your agent speaks
Verifying tool calls#
The judge sees your agent's tool calls, so you can verify them:
workflow: |
1. Ask to book a haircut for tomorrow
2. Verify the agent calls checkAvailability
3. Verify the date argument is tomorrow's date in YYYY-MM-DD format
4. PASS if the tool was called with the correct dateVerifying behavior#
Test what your agent says (or doesn't say):
workflow: |
1. Ask to book on a Sunday
2. Verify the agent says the business is CLOSED on Sundays
3. Verify the agent does NOT call checkAvailability
4. Verify the agent suggests an alternative day
5. PASS if all conditions metJudge Providers#
The judge is the LLM that evaluates your agent. Choose based on cost and reliability:
| Provider | Model | Cost (per 1M tokens) | Notes |
|---|---|---|---|
anthropic | claude-haiku-4-5-20251001 | $0.80 in / $4.00 out | Default. Most reliable. |
openai | gpt-4.1-nano | $0.10 in / $0.40 out | Recommended. 10x cheaper than Haiku. |
google | gemini-2.5-flash | — | Fast, low cost. |
deepseek | deepseek-v4-flash | $0.14 in / $0.28 out | Cheapest cloud option. |
ollama | gemma3:4b | Free | Local. Requires Ollama running. |
Set the judge in the spec file or override with CLI:
# Override all specs to use OpenAI
pinecall test agent/specs/ --judge anthropic/claude-haiku-4-5Environment variables#
Each provider needs its API key:
| Variable | Provider |
|---|---|
ANTHROPIC_API_KEY | Anthropic (default) |
OPENAI_API_KEY | OpenAI |
GOOGLE_API_KEY | |
DEEPSEEK_API_KEY | DeepSeek |
OLLAMA_HOST | Ollama (default: http://localhost:11434) |
CLI Reference#
# Run all specs in a directory
pinecall test agent/specs/
# Run a single spec
pinecall test agent/specs/date-handling.spec.yaml
# Override judge model
pinecall test agent/specs/ --judge anthropic/claude-haiku-4-5
# Override agent name
pinecall test agent/specs/ --agent dev-berna-florencia
# Filter specs by name
pinecall test agent/specs/ --grep "date"
# JSON output (for CI pipelines)
pinecall test agent/specs/ --json
# List specs without running
pinecall test agent/specs/ --list
# Verbose mode (full agent responses)
pinecall test agent/specs/ --verboseCI Integration#
pinecall test exits with code 1 when any spec fails, and supports --json for machine-readable output:
# In your CI pipeline
export PINECALL_API_KEY="pk_..."
export OPENAI_API_KEY="sk-..."
pinecall test agent/specs/ --judge anthropic/claude-haiku-4-5 --jsonJSON output structure:
{
"passed": 2,
"failed": 0,
"results": [
{
"file": "agent/specs/date-handling.spec.yaml",
"agent": "florencia",
"passed": true,
"summary": "All dates verified correctly",
"turns": [...],
"durationMs": 4300
}
]
}Project Structure#
Recommended layout for your agent project:
my-agent/
├── agent/
│ ├── index.js # Agent code
│ └── specs/ # Test specs
│ ├── greeting.spec.yaml
│ ├── booking.spec.yaml
│ └── edge-cases.spec.yaml
└── package.json